The Big Picture
DeepSeek-V4 set the community abuzz the moment it dropped — 1.6 trillion parameters, a million-token context window, and inference costs that are surprisingly well-controlled. So what exactly did they do? Let's tear it down.
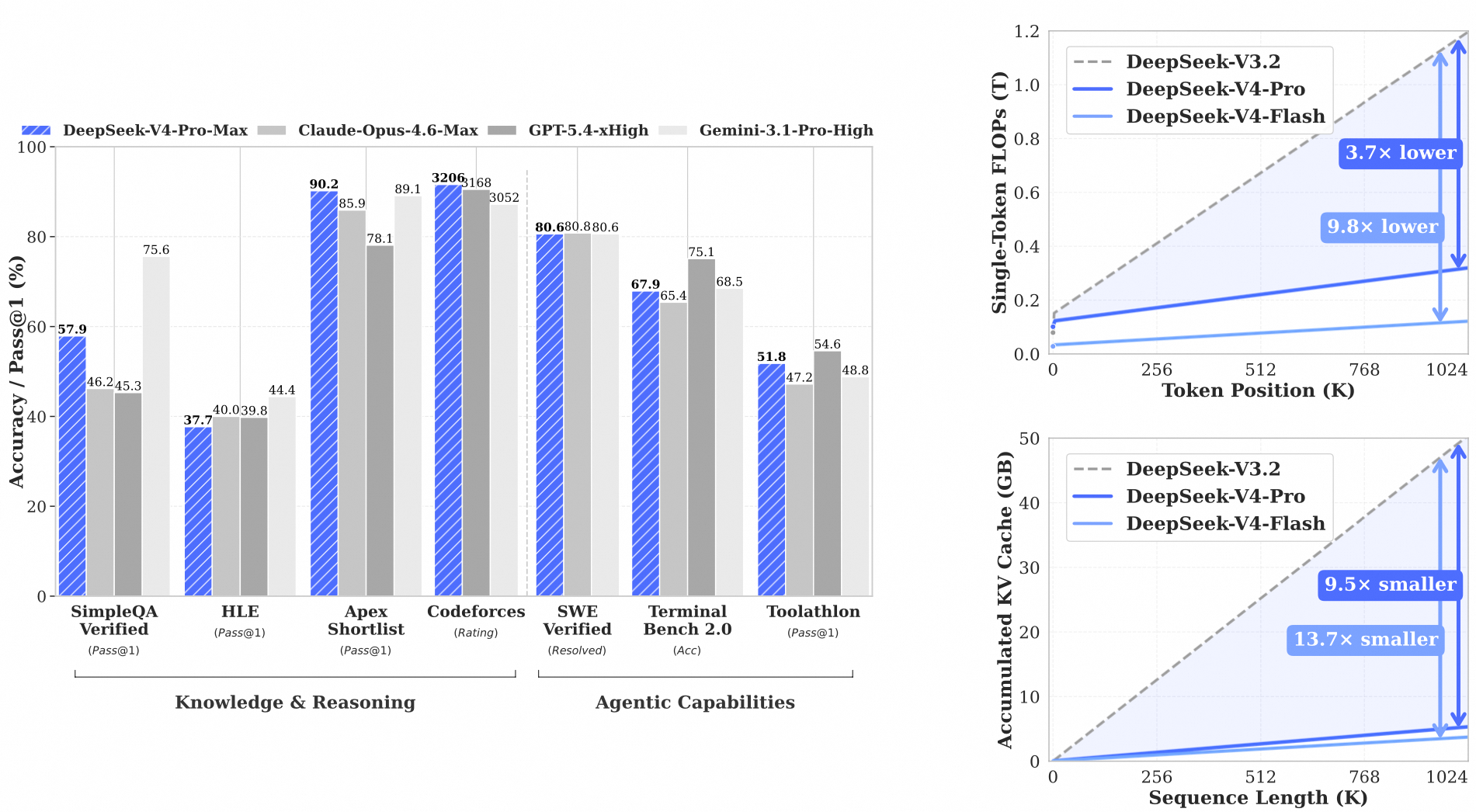
Two Models, One Foundation
The V4 family includes two core models that share the same technical foundation but differ in scale and positioning:
| Feature | DeepSeek-V4-Pro | DeepSeek-V4-Flash |
|---|---|---|
| Total Parameters | 1.6T (1.6 trillion) | 284B (284 billion) |
| Active Parameters | 49B (49 billion) | 13B (13 billion) |
| Context Length | 1,000,000 tokens | 1,000,000 tokens |
| Pretraining Data | 33T tokens | 32T tokens |
Why MoE Works
Both models adopt the DeepSeekMoE framework and a Multi-Token Prediction (MTP) strategy. The core idea behind MoE (Mixture of Experts) is simple: instead of having all parameters participate in every forward pass, you dynamically select a subset of "expert" networks to handle each input. The benefits are clear:
- Massive parameter scale: Total parameters can reach the trillion level
- Controlled inference cost: Only a small fraction of parameters are active per pass (49B for Pro, 13B for Flash)
- Specialized division of labor: Different experts can focus on different knowledge domains or task types
This also means a breakthrough in ultra-long sequence processing — opening up new space for test-time scaling and paving the way for directions like online learning.
From Pretraining to Post-Training
First, pretrain a base model on massive data, then refine it into domain-specific experts through post-training, and finally distill everything into a unified model — that's roughly the V4 training pipeline.
Pretraining Phase
Flash is trained on 32T tokens, while Pro gets 1T more at 33T. The "T" stands for trillion. To put that in perspective — if a person read one word per second, it would take over a million years to read through that much data!
Post-Training Refinement
Post-training involves two key steps:
Independently Cultivating Domain Experts
-
Supervised Fine-Tuning (SFT): The base model is first fine-tuned on high-quality, domain-specific data to establish foundational capabilities.
-
Reinforcement Learning (RL): Optimization is performed using the Group Relative Policy Optimization (GRPO) algorithm. GRPO is an efficient RL method that updates the model by comparing the relative quality of multiple outputs for the same prompt, sidestepping the complexity of training a separate reward model as in traditional RLHF.
Unified Model Integration
All independently cultivated experts are integrated into a single unified model through on-policy distillation. This process ensures that knowledge from different experts fuses effectively, avoiding the "each doing their own thing" problem.
Making Attention Handle a Million Tokens
Processing context lengths at the million-token level poses enormous computational and memory challenges for traditional attention mechanisms. V4 designs two innovative attention architectures: Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA), adopting an interleaved hybrid configuration of the two. The core idea is to aggressively compress the KV cache and combine that with sparse selection, bringing attention complexity down from O(n²) to roughly O(n).
CSA: Compressed Sparse Attention
CSA combines two strategies — compression and sparse attention:
- KV Cache Compression: The Key-Value (KV) cache of every m tokens is compressed into a single entry
- Sparse Attention: Each query token only attends to k compressed KV entries
This design dramatically reduces attention complexity from the traditional O(n²) to approximately O(n).
HCA: Heavily Compressed Attention
HCA goes further than CSA by compressing even more tokens into a single entry. CSA and HCA are used together in an interleaved fashion, striking a balance between compression ratio and precision.
Three Design Tricks That Keep Attention from Blowing Up
RMSNorm Normalization
For CSA and HCA, an additional RMSNorm operation is applied to each query's head and the single head of compressed KV entries, before the core attention computation. This normalization prevents attention logits from exploding and improves training stability.
Partial RoPE Positional Encoding
In V4's architecture, positional encoding is critical for the model to understand the sequential order of tokens. RoPE (Rotary Position Embedding) is the most mainstream positional encoding in large models today, and Partial RoPE is an optimization that V4 designed specifically for its unique attention mechanism (particularly MLA — Multi-head Latent Attention).
Key innovations:
- Mixed-precision storage: BF16 precision for RoPE dimensions, FP8 precision for the remaining dimensions
- Sliding window mechanism: For each query token, n_win additional uncompressed KV entries are generated, corresponding to the most recent n_win tokens. In the core attention of CSA and HCA, these sliding window KV entries are used alongside the compressed KV entries
Teaching Attention to "Ignore"
This is a really clever design!
The traditional pain point: When a query is irrelevant to all keys in the context (e.g., processing irrelevant noise or无效 information at extreme distances), standard Softmax still forces 100% of the weight onto some keys, making the model "forced to attend" to unimportant content and creating interference.
V4's solution: By increasing the learnable parameter z'h, exp(z'h) becomes larger, the denominator grows, and all s{h,i,j} become smaller. The total attention weight can approach zero.
Intuitive understanding: The model can now say: "I've looked through this row, but nothing here seems worth paying attention to," and it "leaks" most of the attention away instead of forcibly allocating it to some token.
Adapting to CSA/HCA's compression mechanism: In CSA and HCA, tokens are compressed into blocks. If the information within a block is sparse or irrelevant, the model can reduce its overall attention to that block by adjusting z'h. This mechanism makes the model more robust when processing ultra-long contexts — it can automatically filter out compressed blocks that "exist but are meaningless," preventing noise accumulation.
FP4 Precision Acceleration
Attention computation within the lightning indexer is executed in FP4 precision, which accelerates attention operations under extremely long contexts. FP4 is 4-bit floating point — compared to traditional FP16 or BF16, memory usage is reduced by 4x and computation speed is significantly improved.
The Evolution of Residual Connections
What's the biggest fear with deep networks? Vanishing and exploding gradients. Residual connections alleviate this problem, but at the scale of trillion parameters and dozens to hundreds of layers, traditional residual connections are no longer sufficient. V4 introduces Manifold-Constrained Hyper-Connections (mHC), adding "mathematical constraints" to residual connections so that signals flow smoothly through deep layers like water through a pipe.
From Residual Connections to Hyper-Connections
Let's compare several connection schemes:
| Feature | Standard Residual Connection | Standard Hyper-Connection (HC) | mHC (DeepSeek-V4) |
|---|---|---|---|
| Residual transform Bₗ | Ordinary linear matrix, unconstrained | Ordinary linear matrix | Doubly stochastic matrix (constrained via Sinkhorn algorithm) |
| Input/Output mapping | - | Ordinary linear matrix | Non-negative bounded (constrained via Sigmoid) |
| Numerical stability | Unstable in deep networks | Moderate | Extremely high, suitable for ultra-deep networks |
| Computational overhead | Very low | Low | Slightly higher (requires Sinkhorn iterations), but acceptable |
| Core purpose | Increase residual width | Increase residual width | Increase width while guaranteeing training stability |
The Core Idea Behind mHC
mHC essentially adds "mathematical constraints" to standard hyper-connections, ensuring that residual signals flow smoothly through deep layers — neither flooding (exploding) nor drying up (vanishing). This is what allows a massive model like V4 to train stably and perform well.
In a doubly stochastic matrix, the sum of every row and every column equals 1, ensuring that information neither infinitely amplifies nor diminishes during propagation. The Sinkhorn algorithm can convert any positive matrix into a doubly stochastic matrix. While this adds computational overhead, for the stability of a trillion-parameter model, the trade-off is absolutely worth it.
Pushing Trillion Parameters with Muon
Training a trillion-parameter model is like pushing a super-heavy cart — ordinary optimizers either can't push it or push it slowly. Muon is like installing a more efficient transmission: you go further with less effort. V4 introduces the Muon optimizer, bringing faster convergence and better training stability. But when Muon meets the ZeRO distributed training strategy, some clever adaptations are needed.
Muon's Challenge
The Muon optimizer requires the full gradient matrix to compute parameter updates, which creates challenges when combined with Zero Redundancy Optimizer (ZeRO). ZeRO is a distributed training optimization technique that reduces memory redundancy by partitioning optimizer states, gradients, and parameters across multiple GPUs.
Hybrid ZeRO Bucket Allocation Strategy
To solve this problem, the DeepSeek team designed a hybrid ZeRO Bucket allocation strategy:
Dense Parameters
-
Limited parallelism + bin-packing algorithm: The maximum scale of ZeRO parallelism is limited, and a bin-packing algorithm assigns parameter matrices to each Rank (GPU/process), ensuring roughly balanced loads across Ranks.
-
Padding alignment: To efficiently execute reduce-scatter communication operations, Buckets on each Rank are padded to match the size of the largest Bucket across all Ranks.
- Overhead: In this setup (each Rank manages no more than 5 parameter matrices), memory overhead is typically under 10%.
-
Oversized data parallelism: When data parallelism (DP) scale exceeds ZeRO's limits, the extra DP groups redundantly compute Muon updates. This is a "trade computation for memory" strategy to reduce total Bucket memory footprint.
MoE Parameters (Mixture of Experts)
-
Independent expert optimization: Each Expert is optimized independently.
-
Flattening and reorganization:
- Flatten and concatenate the down projection matrices from SwiGLU across all layers and all Experts
- Then the up projection matrices
- Finally the gate matrices
-
Overall padding: The concatenated long vector is padded to ensure it can be evenly distributed across all Ranks without splitting any logically independent matrix.
-
No parallelism limit: Due to the large number of Experts, there's no ZeRO parallelism limit for MoE parameters, and padding overhead is negligible.
Other Optimization Tricks
- Batched Newton-Schulz iterations: Consecutive parameters of the same shape on the same Rank are automatically merged, enabling batched Newton-Schulz iterations and improving hardware utilization.
- BF16 stability: Even with BF16 (Bfloat16) precision matrix multiplication, Newton-Schulz iterations in Muon remain stable, further improving computational efficiency.
Squeezing Infrastructure to the Limit
Training and inferencing trillion-parameter models requires more than good algorithms — you have to squeeze every last drop out of the hardware. V4 makes deep optimizations in communication-computation overlap, Kernel DSL, and deterministic computation.
Doing Communication and Computation at the Same Time
In Expert Parallelism (EP), V4 implements a fine-grained EP scheme that fuses communication and computation into a pipelined kernel, achieving communication-computation overlap.
Core idea: Experts are divided into multiple "waves," with each wave containing a small subset of experts. Once all experts within a wave complete communication, computation can begin immediately without waiting for other experts.
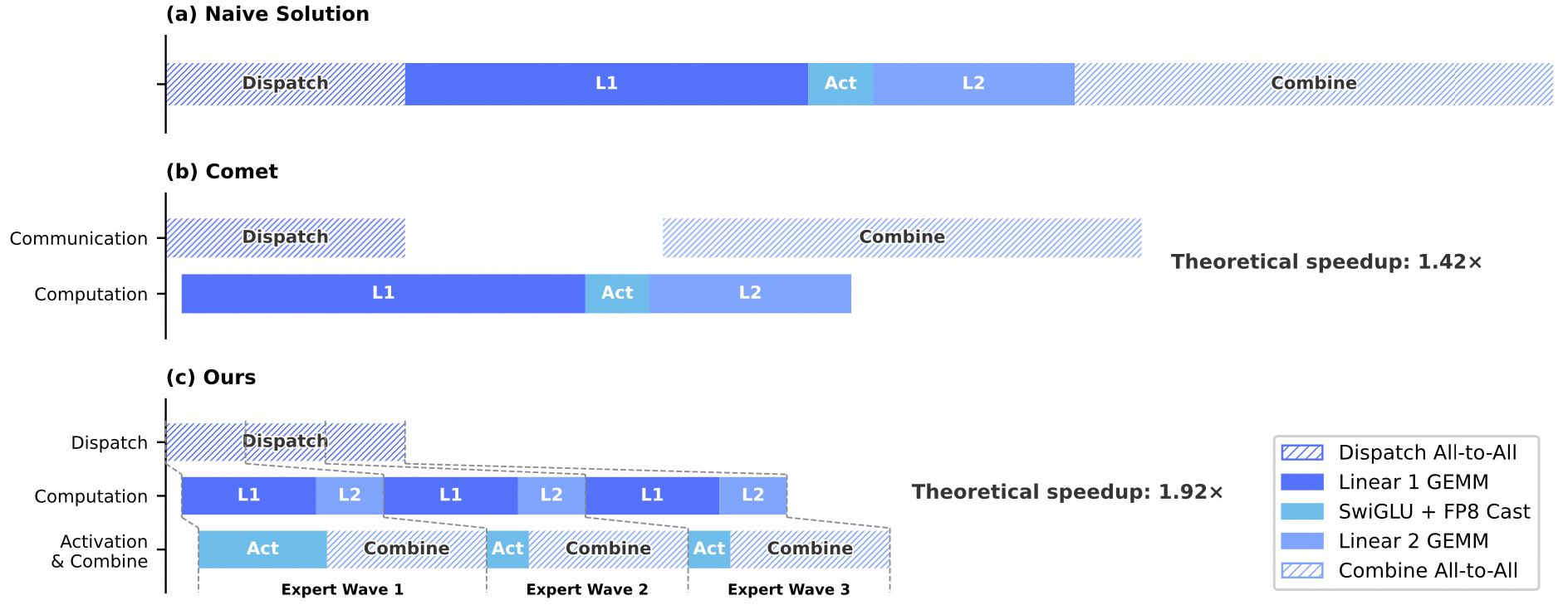
Key insights:
- Full communication-computation overlap depends on the compute-to-communication ratio, not just bandwidth
- Each GBps of interconnect bandwidth is sufficient to hide the communication overhead of 6.1 TFLOP/s of computation
- This directly reduces post-GEMM processing overhead, preventing the GEMM pipeline from being blocked by activation function computation, thereby improving overall compute throughput and resource utilization
TileLang: Making Kernel Code Read Like a High-Level Language
Writing GPU kernels usually forces a choice between performance and developer productivity — either hand-write CUDA for maximum performance but slow development, or use high-level frameworks for fast development but with runtime overhead. TileLang aims for both: describe computation logic with a domain-specific language, while using Host Codegen to drive runtime overhead down to nearly zero.
TileLang generates both the device-side kernel and the host-side launcher at the IR layer. The latter is lowered to native C++ code via TVM-FFI, then executed at runtime through zero-copy tensor interaction and compact calling conventions for validation and marshaling — completely bypassing the Python interpreter and crushing CPU-side scheduling overhead to sub-microsecond levels. Traditionally, host-side logic is written in Python for flexibility, which incurs a fixed per-call cost. Host Codegen eliminates this problem entirely.
Batch-Invariant and Deterministic Kernel Library
V4 provides an efficient batch-invariant and deterministic kernel library, ensuring bit-wise reproducibility between training and inference.
Batch invariance ensures that the output for any given token remains bit-identical regardless of its position within a batch. Non-determinism in training typically stems from non-deterministic accumulation order (e.g., atomic add instructions), which primarily occurs during backpropagation. V4 eliminates this issue through carefully designed kernels.
Splitting a Million Tokens Across Multiple GPUs
Processing million-token contexts — a single GPU's memory simply can't hold it all. V4 designs a Contextual Parallelism (CP) strategy that splits ultra-long sequences across multiple GPUs for parallel processing while ensuring that compressed KV caches remain aligned and consistent in a distributed environment.
Two-Phase Communication Strategy
Boundary Data Exchange and Local Compression
To handle the case where a compression window might straddle two Ranks:
- Each Rank i sends its last m uncompressed KV entries to the next Rank i+1
- Rank i+1 merges these received boundary entries with its local data and performs compression, producing a compressed KV block of fixed length (with minor padding)
This ensures token integrity within each compression group, avoiding feature distortion caused by splitting across boundaries.
Global Gathering and Unified Reorganization
- All CP Ranks exchange their locally compressed KV blocks via an All-Gather operation
- A fused Select-and-Pad operator reassembles the scattered blocks into a globally contiguous compressed KV sequence with total length cp_size · m · s
- All padding is uniformly moved to the end of the sequence
Index Visibility Handling
- For HCA and CSA indexers, the range of compressed KV entries visible to each query can be precomputed by rule
- For CSA sparse attention, the Top-k selector directly specifies the visible compressed KV indices
This approach guarantees both the mathematical correctness of compression — windows won't be truncated across boundaries — and efficient alignment of distributed KV caches. Long-context training parallel efficiency goes up as a result.
Squeezing Memory Down to Every Tensor
When training large models, activations consume a significant amount of GPU memory. The traditional approach is to do checkpointing at the module level, but the granularity is too coarse — either you don't save much memory, or the recomputation overhead is too high. V4's solution goes down to the tensor level: mark which tensors you want to recompute, and the framework handles the rest automatically.
Limitations of the Traditional Approach
Traditional activation checkpointing mechanisms operate at module-level granularity, which is suboptimal in the trade-off, while manually implementing fine-grained control has extremely high development complexity.
V4's Innovative Approach
V4 proposes a TorchFX-based tensor-level automatic activation checkpointing mechanism. Developers simply annotate which tensors need recomputation during the forward pass, and the framework automatically traces the computation graph, reverse-traverses to find the minimal recomputation subgraph, and dynamically inserts it into backpropagation — all without writing a single line of backward pass logic.
Performance Optimizations
There are also two practical optimizations: zero-copy memory management directly frees GPU memory for annotated tensors and reuses storage pointers after recomputation; automatic deduplication uses graph tracing to monitor underlying storage pointers in real time, automatically identifying and deduplicating tensors that share storage space (e.g., the input and output of a Reshape operation).
Put simply, you write PyTorch code as usual, and the framework automatically squeezes memory down to the finest granularity behind the scenes. No extra backward pass code needed, and no slowdown in training.
What V4 Brings to the Table
V4's most fundamental breakthroughs come down to three things. First, the CSA/HCA hybrid attention makes million-token context not just theoretically possible but an engineering reality — with controllable inference costs. Second, the combination of mHC hyper-connections and the Muon optimizer means trillion-parameter models can not only be trained, but trained stably and quickly. Third, from contextual parallelism to tensor-level checkpointing, a comprehensive suite of engineering optimizations squeezes hardware to its absolute limit.
For the industry, V4's message is clear: simply stacking parameters has hit a bottleneck — architectural innovation and engineering optimization are the keys to continued progress. Only by reducing inference costs while maintaining high performance can large models truly be deployed in practice. DeepSeek has consistently upheld an open-source philosophy, driving the entire industry forward together, and that deserves recognition.
This also means that the breakthrough in ultra-long sequence processing opens up new space for test-time scaling and paves the way for online learning and continual learning. We can expect context windows to continue expanding to tens of millions or even hundreds of millions of tokens, inference algorithms to become increasingly efficient, and domain-specific capabilities to keep strengthening. Even more exciting is the breakthrough in online and continual learning — models will no longer only learn during training but will be able to evolve continuously during use.
References
- DeepSeek-V4 Technical Report
- DeepSeekMoE Framework (Dai et al., 2024)
- Multi-Token Prediction Strategy
- Compressed Sparse Attention (DeepSeek-AI, 2025)
- Manifold-Constrained Hyper-Connections (Xie et al., 2026)
- Muon Optimizer (Jordan et al., 2024; Liu et al., 2025)
- Zero Redundancy Optimizer (Rajbhandari et al., 2020)
- TileLang (Wang et al., 2026)
If you found this article helpful, feel free to like and bookmark it. Questions and discussions are welcome in the comments.