Paper: Greyhound: Hunting Fail-Slows in Hybrid-Parallel Training at Scale Authors: Tianyuan Wu, Wei Wang (HKUST); Yinghao Yu, Siran Yang, Wenchao Wu, Guodong Yang, Jiamang Wang, Lin Qu, Liping Zhang (Alibaba Group); Qinkai Duan (HKUST) Published: USENIX ATC 2025
TL;DR
In large-scale hybrid-parallel training, GPUs and network links sometimes don't crash outright — they just "slow down". This is fail-slow. GREYHOUND hooks NCCL calls for non-invasive iteration time tracking, uses BOCD algorithm for online anomaly detection, then applies lightweight profiling + micro-benchmarks to pinpoint slow components. For mitigation, it borrows from the ski-rental problem to design a four-level progressive strategy from "do nothing" to "checkpoint restart". Detection accuracy >99% on production clusters with 10,000+ GPUs, 1.58x throughput improvement in 256 H800 experiments.
Key Insights
-
Fail-slow is not a rare anomaly — it's the norm in large-scale training. In 10,000-GPU clusters, 16 out of 27 large-scale training jobs encountered fail-slow, with average JCT (Job Completion Time) delay of 34.59% — compared to ideal scenarios without fail-slow. This shows that "partially broken" components are more common and more troublesome than "completely broken" ones at this scale. Supported by data.
-
Communication fail-slow is far more severe than compute fail-slow. Compute fail-slow (CPU contention, GPU throttling) has low frequency (<2%) and short duration (mean 10 minutes); communication fail-slow (network congestion) has high frequency (40%) and long duration (mean 24 minutes), frequently overlapping in large-scale training, causing slowdown far exceeding compute issues. Supported by data.
-
The core contradiction in detecting fail-slow: all GPUs slow down together, but only one is the culprit. Synchronous training's inherent property causes one slow component to drag down the entire system — monitoring metrics (like SM utilization) drop on all GPUs simultaneously, traditional node-level telemetry cannot locate the root cause. GREYHOUND's solution uses communication patterns of different parallel groups in hybrid parallelism for "cross-group comparison", filtering out slowed groups from normal ones. No data support (design insight).
-
Mitigating fail-slow is an online decision problem, not simply "restart". Traditional approach treats fail-slow as fail-stop — checkpoint + restart, but GPT2-100B checkpoint takes nearly 100 minutes, longer than most fail-slow durations. GREYHOUND borrows from ski-rental problem, letting the system progressively upgrade from low-overhead strategies until cumulative slowdown loss exceeds the cost of higher-overhead strategies, then switch. Supported by data.
Open Question: GREYHOUND's current detection mechanism relies on hooking NCCL's top-level interface — if training frameworks use non-standard communication libraries or custom collective communication primitives, how should hook points be adapted?
Background and Motivation
Hybrid-Parallel Training: Why So Complex?
Training trillion-parameter models requires coordination across thousands of GPUs — single parallelism strategy cannot balance efficiency:
| Parallelism Strategy | Principle | Communication Volume | Scope |
|---|---|---|---|
| TP (Tensor Parallelism) | Split single operator across GPUs | Large (every operator needs synchronization) | Within single node |
| DP (Data Parallelism) | Replicate model, shard data | Medium (gradient synchronization) | Within/across nodes |
| PP (Pipeline Parallelism) | Partition by layers, micro-batch pipeline | Small (only pass activations) | Across nodes |
Hybrid parallelism = TP + DP + PP combination, maximizing training efficiency while making fault propagation paths extremely complex.
Fail-stop vs. Fail-slow
| Dimension | Fail-stop | Fail-slow |
|---|---|---|
| Manifestation | Process crash, GPU hang | GPU/network slows but still running |
| Detection | Easy (heartbeat lost) | Hard (all GPUs slow together) |
| Existing Solutions | Checkpoint + restart, elastic frameworks | Lack systematic approach |
| Root Cause | Hardware failure, runtime errors | CPU contention, thermal throttling, network congestion |
Existing solutions mainly address fail-stop, only "mentioning but not deeply exploring" fail-slow. Llama 3 report and MegaScale briefly mention fail-slow but lack systematic characterization and solutions.
Fail-slow Status in 10,000-GPU Clusters
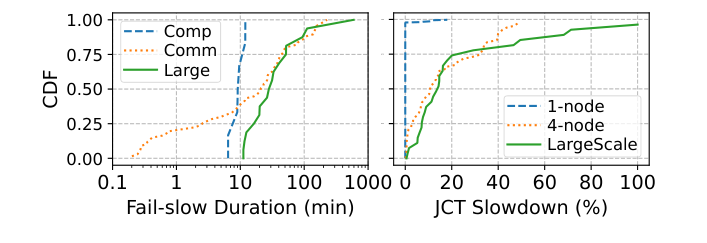
The paper provides systematic characterization on Alibaba production cluster (4000+ nodes, 10000+ GPUs, RoCE 400Gbps):
Small-scale probing (400 single-node jobs):
- Among 392 successfully completed jobs, 6 encountered compute fail-slow (4 CPU contention, 2 GPU throttling)
- Compute fail-slow averaged 10 minutes, JCT increased 11.79%
- Among 107 4-node jobs, communication fail-slow occurrence rate 40%, average duration 24 minutes
Large-scale actual jobs (27 jobs with ≥512 GPUs):
- 16 encountered fail-slow, average JCT increase 34.59%
- 20% of jobs delayed over 50%
- Average fail-slow duration 72 minutes
- Root cause: 13 pure network congestion, rest were network + GPU throttling combined
Core Methods
Overall Architecture
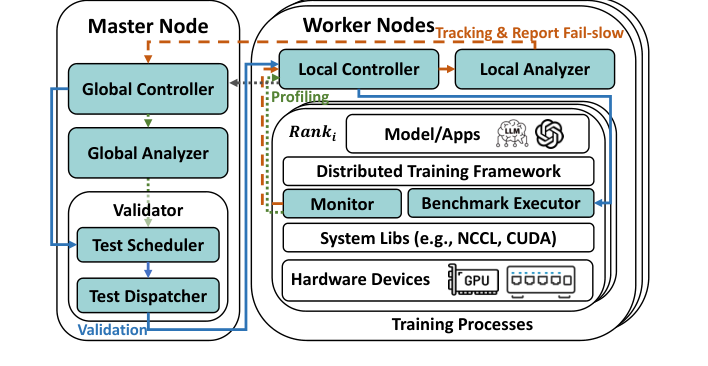
GREYHOUND adopts master-worker architecture, detection flow has three stages: Tracking → Profile → Validation.
Stage 1: Tracking
This is the most critical and clever part — non-invasive, only hooking NCCL calls.
Iteration Time Inference: In training loops, collective communication operations (AllReduce, AllGather, ReduceScatter) exhibit periodic patterns. GREYHOUND uses autocorrelation function (ACF) to automatically infer period length from communication call sequences:
$$\text{ACF}(X)k = \frac{\text{Cov}(X_t, X{t+k})}{\text{Var}(X_t)} = \frac{\sum_{t=1}^{L-k}(X_t - \mu)(X_{t+k} - \mu)}{\sum_{t=1}^{L}(X_t - \mu)^2}$$
Where $X$ is communication call timestamp sequence, $k$ is candidate period length, $\mu$ is sequence mean. Larger $\text{ACF}(X)_k$ means higher likelihood that $k$ is the true period. Take the first $k$ exceeding threshold $M=0.95$:
$$\text{Period} = \arg\min_k (\text{ACF}(X)_k \geq M)$$
After inferring period, iteration time = interval between same communication operation in adjacent periods.
Anomaly Detection — BOCD + Validation: After obtaining iteration time sequence, use Bayesian Online Changepoint Detection (BOCD) algorithm to find changepoints online. BOCD maintains a run-length $r_t$ for each timestep $t$: if not a changepoint then $r_t = r_{t-1} + 1$, otherwise reset to 0. Calculate posterior probability of $r_t = 0$ through Bayesian inference, report changepoint if exceeding threshold 0.9.
But BOCD has false positives (normal jitter judged as changepoint), so added validation: compare average iteration time before and after changepoint, differences <10% treated as normal jitter and ignored.
Stage 2: Profile
After detecting slow iterations, need to locate which parallel group has problems. GREYHOUND injects CUDA events into hooked NCCL calls on each worker, measuring execution time of each communication group.
Core idea is cross-group comparison: In hybrid parallelism, same-type communication groups process identical data volumes, execution times should be consistent. For example, 4 DP groups have same AllReduce communication volume — if one group is significantly slower than others, it contains a straggler. Judgment standard: groups with execution time exceeding intra-group median by 10% marked as suspicious.
DP-0 AR0 ████████████ 1.2s
DP-1 AR1 ████████████ 1.1s
DP-2 AR2 ████████████ 1.1s
DP-3 AR3 ████████████████████ 1.8s ← Suspicious!
Stage 3: Validation
Profile only locates suspicious groups, need to precisely find which GPU or which link is slow within the group. Approach: briefly suspend training (by trapping NCCL calls, no restart needed), then run micro-benchmarks:
Compute Validation: Run GEMM benchmarks (FP8/FP16/FP32) on all GPUs in group, exclusively using all SM cores to measure true performance.
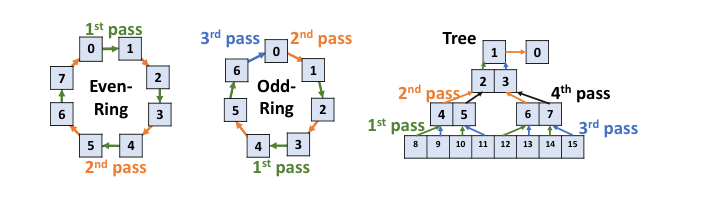
Communication Validation: One of the most clever designs — instead of exhaustively testing all $O(N^2)$ links, utilize Ring/Tree topology structure of collective communication, decompose collective ops into non-overlapping P2P operations, $O(1)$ rounds cover all links:
- Ring topology: Even-rank Ring covers in two rounds (even→odd, odd→even), odd-rank adds one round
- Tree topology: Four rounds cover (even-level left→parent, even-level right→parent, odd-level left→parent, odd-level right→parent)
In each round, same-direction transfers execute in parallel, so duration is independent of group size.
Mitigation Mechanism: Four-Level Strategy Inspired by Ski-Rental
After detecting fail-slow, how to handle it? GREYHOUND designs four-level progressive mitigation:
| Strategy | Overhead | For Compute Fail-slow | For Communication Fail-slow |
|---|---|---|---|
| S1: Ignore | None | Ineffective | Ineffective |
| S2: Adjust Micro-batch Distribution | Low | Effective | Ineffective |
| S3: Adjust Parallel Topology | Medium | Effective | Effective |
| S4: Checkpoint + Restart | High | Eliminates | Eliminates |
Why not use S4 immediately? Because GPT2-100B checkpoint takes nearly 100 minutes, while average fail-slow in cluster is only 10-72 minutes — restart is slower than waiting for recovery.
S2: Adjust Micro-batch Distribution
Data parallelism splits global batch into micro-batches evenly distributed across DP groups. When one group slows down, reduce its micro-batch count, increase normal groups' counts, making all groups' processing times converge:
$$\min_{m_1,\ldots,m_D} \max_{i=1,\ldots,D} m_i t_i \quad \text{s.t.} \quad m_i \in \mathbb{N}^+, \quad \sum_{i=1}^{D} m_i = M$$
Where $D$ is DP group count, $M$ is total micro-batch count, $m_i$ is micro-batches assigned to group $i$, $t_i$ is time for that group to process one micro-batch (obtained from profiling). Essentially minimizing the slowest group's time, solved with cvxpy.
Key: micro-batch counts change, but global batch size and micro-batch size remain unchanged, use weighted average during gradient aggregation to ensure training correctness.
S3: Adjust Parallel Topology
Two core operations for communication fail-slow:
1. Swap congested links from heavy-traffic groups to light-traffic groups. DP communication volume far exceeds PP (DP synchronizes tens of GB gradients each time, PP only passes tens to hundreds of MB activations). If a congested link is being used by DP group, can swap nodes' DP/PP roles to "move" this link to PP group, letting light traffic use congested link, heavy traffic use healthy links.
Before: After:
DP ─── [congested] ─── PP ─── [congested] ───
PP ─── healthy ─── DP ─── healthy ───
2. Straggler Consolidation. When multiple stragglers are scattered across different PP stages, each stage is dragged down. Consolidate all stragglers into minimum number of PP stages — since within same stage the slowest is taken as baseline, multiple stragglers in one stage don't compound deterioration.
Topology adjustment implementation: suspend training → dump parameters to memory → P2P RDMA exchange parameters → resume training. Takes about 1 minute, independent of training scale (each GPU operates independently).
Ski-Rental-Style Decision
When to upgrade from S1 to S2, from S2 to S3? This problem is isomorphic to classic ski-rental problem:
- "Rent skis" = Continue enduring slowdown from fail-slow
- "Buy skis" = Pay strategy switch overhead once and for all
Algorithm tracks cumulative slowdown caused by fail-slow (slow_iters × (t_slow - t_healthy)), switch when cumulative slowdown equals next-level strategy's overhead — because if we knew it would be slow this long, we should have used that strategy from the start.
def mitigation_planner(event):
candidates = find_strategies(event.root_cause)
candidates.sort(key=lambda s: s.overhead)
id = 0 # current strategy
while event.persist():
slow_iters = event.get_slow_iters()
slow_impact = slow_iters * (t_slow - t_healthy)
if slow_impact >= candidates[id].overhead:
candidates[id].apply()
id += 1
Experimental Analysis
Detection Accuracy
| Algorithm | Compute Accuracy | Compute FPR | Communication Accuracy | Communication FPR |
|---|---|---|---|---|
| Sliding Window | 99.5% | 0.0% | 93.5% | 1.5% |
| BOCD | 77.8% | 18.4% | 69.2% | 34.0% |
| BOCD+V | 100% | 0.0% | 99.1% | 0.0% |
BOCD+V (with validation) achieves perfect accuracy on compute fail-slow, only 2.3% FNR on communication (from rare cases of continuous <10% slowdown). Standalone BOCD has FPR as high as 18-34%, validation step pushes false positives to zero.
Mitigation Effectiveness
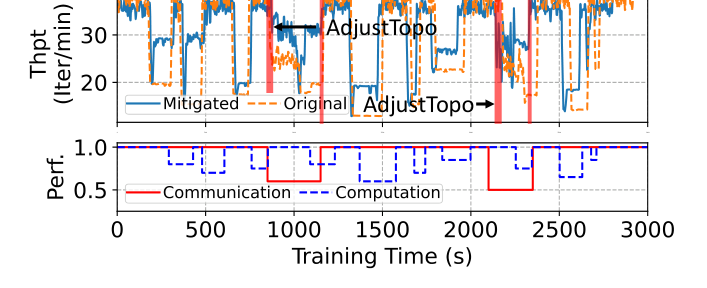
S2 Micro-batch Adjustment: In single-node 8 GPU experiments, after injecting weak/medium/severe compute fail-slow, iteration time reduced from 1.7x baseline to 1.1-1.3x, up to 1.59x optimization. When multiple slow DP groups, optimization space decreases (can't adjust if all groups are slow).
S3 Topology Adjustment: In 2-node 16 GPU experiments, PP=4 severe congestion reduced iteration time up to 1.23x, PP=8 1.14x. Straggler consolidation: 2 stragglers scattered across different stages caused 1.7x slowdown, consolidated to 1 stage reduced to 1.3x.
End-to-end: 256 H800 GPU (8TP, 16DP, 2PP) experiment, injecting 12 fail-slow events (2 communication + 10 compute + compound scenarios):
- Without GREYHOUND: throughput 18.9 iter/min
- With GREYHOUND: throughput 29.8 iter/min
- 1.58x improvement
Overhead
- Tracking stage: average overhead 0.39%, max 1.1%
- Validation stage: compute benchmark <1 second on H800, communication benchmark <3 seconds
- Micro-batch adjustment solving: ~36 seconds for 512 DP groups
- Topology adjustment: ~1 minute (scale-independent)
- Compared to C/R: topology adjustment 6.72x faster than disk checkpoint
Deep Understanding Q&A
Q1: Why hook NCCL calls instead of directly monitoring GPU metrics?
Directly monitoring GPU SM utilization, NVML temperature etc. seems simpler, but has a fatal problem in synchronous training: one GPU slows down, all GPUs' SM utilization drops (because synchronization barrier causes other GPUs to wait). Metric-level "all cards slow" cannot distinguish "who is cause and who is effect". Hooking NCCL benefits: can precisely measure each communication group's time, through cross-group comparison find the truly slow group. Additionally, NCCL top-level interface is unified across different communication libraries (ACCL, MSCCL etc.), ensuring framework independence.
Q2: What are prerequisites for ACF iteration period inference? What if training has no obvious periodicity?
ACF method's prerequisite is communication operations in training loop exhibit periodic patterns — this holds in all mainstream hybrid-parallel training frameworks, because each iteration's communication pattern is highly repetitive. If training dynamically changes parallelism strategy (like elastic training), periodic pattern breaks, ACF needs to re-converge. Paper doesn't discuss this dynamic scenario,推测 after topology adjustment ACF automatically re-detects new period.
Q3: How is topology adjustment's "swap node DP/PP role" implemented? How are parameters moved?
Four steps: 1) Suspend training (trap NCCL calls); 2) Temporarily dump GPU parameters to host memory; 3) Directly exchange parameters between nodes via P2P RDMA; 4) Resume training. Since each GPU operates independently, migration time is independent of cluster scale, only depends on single-card parameter count. 80GB parameter migration on H800 takes about 1 minute. Compared to traditional C/R needing disk write then read back, memory direct transfer + RDMA bypasses I/O bottleneck, ~6.7x faster.
Q4: Is ski-rental model here an over-formalization? Can we just use fixed threshold to switch strategies?
Fixed threshold problem: threshold set high, short fail-slow wastes waiting; set low, persistent fail-slow switches too late. Ski-rental's core insight is "switch when cumulative loss equals strategy overhead" — this gives optimal online decision without prior knowledge, competitive ratio 2 (worst case no more than 2x optimal strategy). This is not decorative formalization, gives theoretical guarantee for switch timing. In practice S2 overhead extremely low (second-level solving), S3 medium (~1 minute), S4 extremely high (tens to hundred minutes), this magnitude difference makes progressive strategy far more robust than fixed threshold.
Q5: Can GREYHOUND work on non-Megatron-LM frameworks (like DeepSpeed)?
Detection part (GREYHOUND-DETECT) is completely framework-independent — it only hooks NCCL top-level interface, doesn't depend on training framework internals, DeepSpeed, PyTorch FSDP etc. can directly use. Mitigation part (GREYHOUND-MITIGATE) needs framework-level support (modify micro-batch allocation logic, support runtime topology adjustment), currently implemented as Megatron-LM plugin, migrating to other frameworks needs adapting micro-batch scheduling and parameter exchange interfaces, engineering effort not huge but not zero cost.
Summary
Core Contributions
- First systematic characterization of fail-slow in 10,000-GPU clusters — quantified frequency, duration, impact of compute/communication fail-slow, revealed communication issues far more severe than compute issues, provided baseline data for future research.
- Non-invasive, framework-independent detection — NCCL hook + ACF iteration period inference + BOCD online changepoint detection + cross-group comparison profile + O(1) link validation, high-precision detection without modifying training framework, can directly deploy to existing production environments.
- Multi-level mitigation mechanism inspired by ski-rental — four-level progression from "ignore" to "restart", auto-upgrade when cumulative slowdown exceeds strategy overhead, theoretical competitive ratio 2, first to provide theoretically-guaranteed online decision framework for fail-slow mitigation.
Limitations
- Cannot detect compute-communication coupled fail-slow (extremely rare but exists)
- Mitigation mechanism depends on framework modification, not completely non-invasive
- Continuous small slowdown (<10%) may be missed by validation step
Applicable Scenarios
✅ Large-scale hybrid-parallel training (TP+DP+PP) ✅ Multi-tenant shared clusters (CPU contention, network congestion frequent) ✅ Frameworks using NCCL communication library (Megatron-LM, DeepSpeed etc.) ✅ Long-running training jobs needing 7×24 unattended operation
❌ Training frameworks not using NCCL (need to adapt hook points) ❌ Elastic training scenarios (frequently changing parallelism, ACF period inference needs re-convergence) ❅ Scenarios sensitive to <10% progressive degradation
Paper link: USENIX ATC 2025