Paper: Idleness is Relative: Exploiting Tool-Call Idle Windows for Offloading in Agentic Systems with MORI Authors: Tian Xia, Hanchen Li, Zhifei Li, Xiaokun Chen, Hao Kang, Yifan Qiao, Yi Xu, Ion Stoica (UC Berkeley et al.) Published: arXiv 2026
TL;DR
In one sentence: With Agentic workloads (the loop of推理-reasoning → tool-call → reasoning → tool-call), KV Cache doesn't fit in GPU memory — but which requests should be offloaded to CPU?
Previous approaches used binary decisions — "has it been accessed recently?" or "is it waiting for a tool call?" — keeping each request either on GPU or CPU. The problem is these decisions are too coarse: a request might have been "recently accessed" but is about to enter a 30-second tool-call waiting period, hogging GPU memory for no reason.
MORI's idea is simple: compute an idleness score between 0 and 1 for each request (the proportion of time spent waiting for tool calls), then sort by score. Low-scoring (busy) requests stay on GPU; high-scoring (idle) ones move to CPU. Combined with a dynamic mechanism to adjust GPU/CPU partition sizes, this achieves 20-71% throughput improvement and 18-43% TTFT reduction over the best baseline on real Claude Code coding agent tasks.
First, Let's Clarify: What Exactly Is the Problem?
To understand MORI, we need to get a few concepts straight first.
What Is KV Cache and Why Does It Run Out?
During LLM inference, every generated token needs to reference the K and V vectors (KV Cache) from all previous tokens. These vectors are stored in GPU HBM. A 7B model handling a 4K context conversation occupies roughly a few hundred MB of KV Cache. With high concurrency — say 100 simultaneous conversations — that's tens of GB.
GPU HBM is precious. An H200 typically has only 80GB. A Qwen-2.5 7B model alone takes ~14GB for weights. When the remaining 60GB isn't enough for KV Cache, we have to move some conversations' KV Cache to CPU memory or even disk — this is offloading.
Offloading Has a Cost — Can't Just Move Anything
Moving KV Cache from GPU to CPU and back takes time. Copying a 500MB KV Cache from HBM to DDR5 takes a few milliseconds, and the reverse is similar. But if a program offloaded to CPU immediately needs to generate tokens again (tool call returned instantly), it has to be moved back — this round-trip overhead actually worsens latency.
So the core of offloading is a prediction problem: How long will this request need GPU next? If it's about to use it soon, don't move it; if it's idle for a long time, offloading makes sense.
Agentic Workloads Make This Problem Harder
Regular chat conversations follow "user sends → model replies → user sends again." But Agentic programs are cyclical:
- Model generates reasoning tokens (thinking about what tool to call next) → uses GPU
- Generates tool-call instructions → tool executes (file I/O, code execution, API calls, etc.) → no GPU, waiting for results
- Tool results return, model continues generating → uses GPU again
The problem is the waiting time in step 2. It can be:
- A few milliseconds: a local math calculation tool returns instantly
- A few hundred milliseconds: a database query
- A few seconds: a network API call
- Tens of seconds or even minutes: waiting for user confirmation, executing time-consuming scripts
Time spans range from 10⁻³ seconds to 10² seconds — a difference of 5 orders of magnitude.
Why Existing Methods Fall Short
Now that we understand the problem, the limitations of existing methods become clear.
Method 1: LRU (Least Recently Used)
LRU says: "Move the KV Cache that hasn't been used in the longest time."
But LRU only looks at "when was the last access" — not "what will this request do next." In agentic scenarios, a request might have just finished generating a tool-call instruction (so it was "recently accessed"), but now needs to wait 30 seconds for the tool to return — LRU considers it "hot" and keeps it on GPU. But it doesn't need GPU at all.
The worse reverse problem: A request is actually busy generating tokens (busy phase), but because other requests are running on GPU, its "last access time" becomes stale. LRU will offload it — but it was actually very active.
Method 2: Binary busy/idle Labels
This is a natural improvement: detect "is this request waiting for a tool call to return?" If yes, label idle and offload to CPU; otherwise label busy and keep on GPU.
But in reality, "waiting or not" isn't a binary question. For example:
- Request A: generating reasoning tokens, completely busy (idleness ≈ 0)
- Request B: just sent an HTTP request, typically returns in 200ms (idleness ≈ 0.3)
- Request C: waiting for user to click a button, could be seconds or minutes (idleness ≈ 1.0)
If GPU can only fit 2 requests, binary labels would say: "A busy → stay on GPU, B idle → move to CPU, C idle → move to CPU." But actually B and C's "idleness" differs by an order of magnitude — B might be back soon, and offloading it only to move it back wastes resources.
The fundamental problem with binary labels: they discard the "how idle" information. All idle requests are treated the same, even though some are actually quite "busy."
Method 3: Fixed Timer
Someone might say: just set a timer — offload a request if it hasn't been active for 500ms.
But with time spans ranging from milliseconds to minutes, no fixed value works:
- Set too short (e.g., 100ms): many requests that return after 150ms get unnecessarily offloaded, wasting round-trip overhead
- Set too long (e.g., 10s): requests waiting 30 seconds occupy GPU memory for 10 seconds, underutilizing resources
- The optimal value varies with different tasks, system configurations, and concurrency levels — there's no universal setting
MORI's Approach
MORI does three things:
1. Replace Binary Labels with Continuous Idleness Scores
For each request p, idleness is defined as:
That's "time waiting for tool calls" divided by "total time." 0 means never waiting (pure inference), 1 means always waiting (pure tool calls).
This score is continuous and relative — continuous in that it captures degree, relative in that it only makes sense compared to other requests.
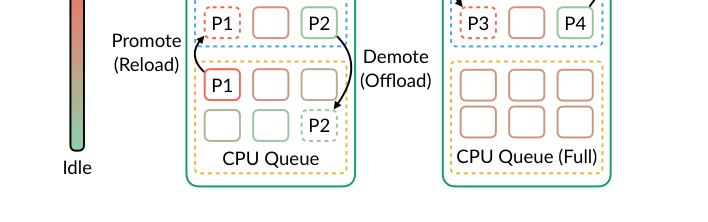
2. Sort by Idleness and Partition into Tiers
Sort all requests by idleness score (low to high), then divide into three tiers:
- GPU Queue: lowest idleness requests, stored in GPU HBM
- CPU Queue: medium idleness requests, stored in CPU DRAM
- Swap: highest idleness requests, stored on disk/NVM
The key is that these tier boundaries aren't fixed — they adjust dynamically based on GPU and CPU pressure.
3. Dynamically Adjust Partition Boundaries
The system monitors GPU and CPU pressure in real-time. If GPU memory is tight (many requests queued for GPU slots), it lowers the GPU partition boundary — demoting relatively higher-idleness requests that are still on GPU to CPU. Conversely, if CPU memory is tight but GPU has space, it promotes requests back to GPU.
This dynamic adjustment solves the "fixed timer doesn't work" problem — no fixed threshold needed, the system decides who should move based on current resource pressure.
Experimental Results
Tested on real Claude Code coding agent tasks with models including Qwen-2.5 7B, Qwen-3 30B-A3B, and Llama-3.1 70B.
Baseline SMG is the current SOTA general offloading method; TA+O is the Token Attention + Offloading approach.
| Configuration | Metric | MORI vs SMG | MORI vs TA+O |
|---|---|---|---|
| H200 + Qwen-2.5 7B (DP=1) | Throughput | +71% | +20% |
| H200 + Qwen-2.5 7B (DP=1) | TTFT | -43% | -18% |
MORI's advantage grows with higher concurrency (e.g., 80 users) — higher concurrency means tighter resources, making the "who to offload" decision more critical and impactful.
Key Takeaways
- The idleness concept itself isn't mathematically sophisticated — it's just a time ratio. MORI's contribution is using it as the core decision signal for offloading and proving it outperforms LRU or binary labels in agentic scenarios.
- Tiered queues + dynamic boundaries are MORI's engineering innovations. Continuous scores solve the "degree" problem; dynamic boundaries solve the "fixed threshold doesn't work" problem.
- The paper doesn't quantify scheduling overhead — a遗憾. Idleness sampling and sorting, promote/demote decisions, and data migration all have costs. The paper claims scheduling frequency is far lower than tool-call frequency, so amortized overhead is acceptable, but provides no specific numbers.
- For non-agentic workloads, MORI's idleness metric degrades to request interval — not very discriminative. But the tiered architecture itself remains effective; it's just that the idleness signal is less useful.
One-line summary: When resources are tight, don't just ask "who used it recently" — ask "who actually needs it now." The latter is a more discriminative signal in agentic scenarios.