先看全貌
DeepSeek-V4 刚发布就炸了圈——1.6 万亿参数、百万 token 上下文、还把推理成本控制得相当漂亮。它到底做了什么?我们拆开来看。
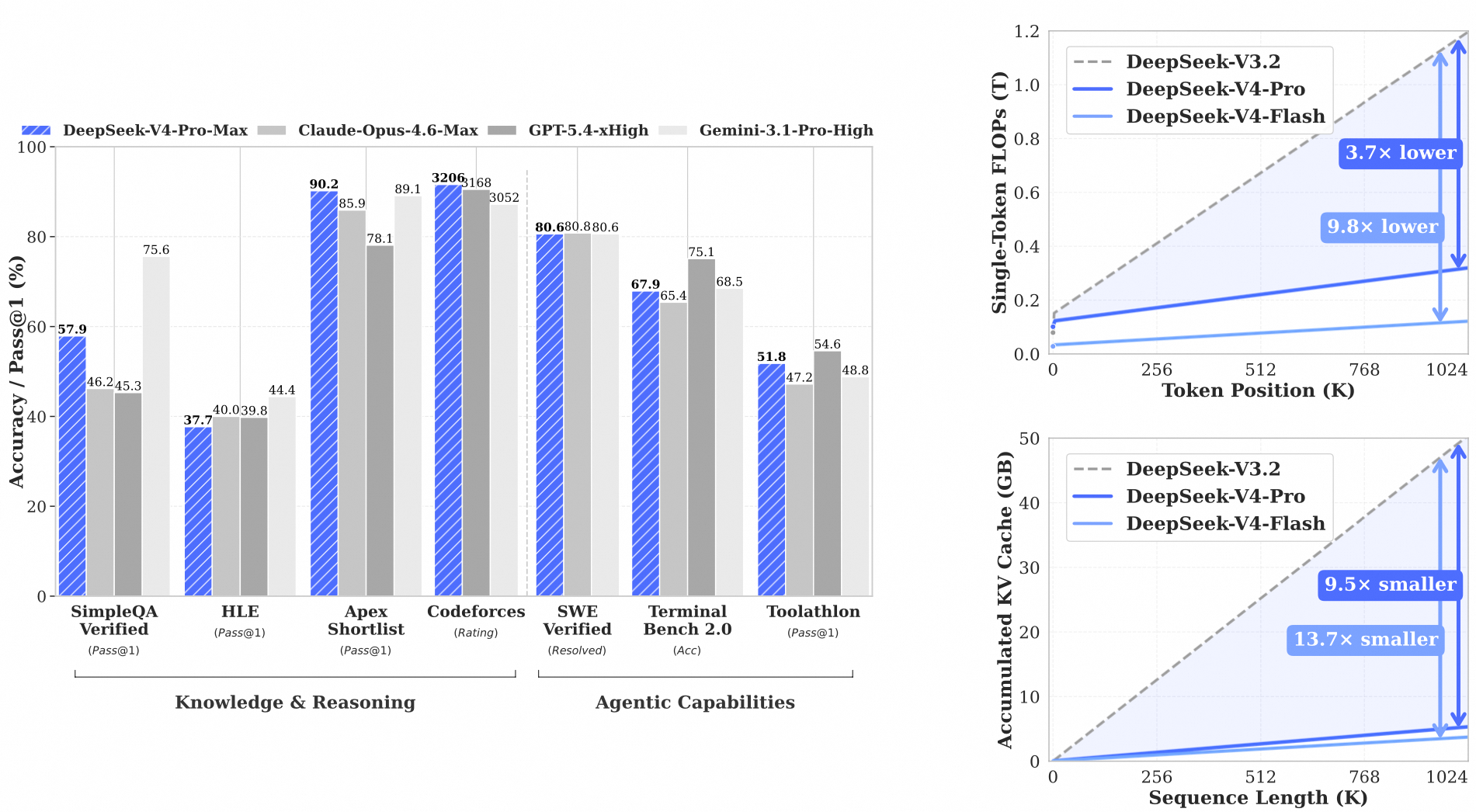
双雄并立
V4 系列包含两个核心模型,它们共享相同的技术底座,但在规模和定位上各有侧重:
| 特性 | DeepSeek-V4-Pro | DeepSeek-V4-Flash |
|---|---|---|
| 总参数量 | 1.6T (1.6万亿) | 284B (2840亿) |
| 激活参数 | 49B (490亿) | 13B (130亿) |
| 上下文长度 | 1,000,000 tokens | 1,000,000 tokens |
| 预训练数据 | 33T tokens | 32T tokens |
MoE 为什么管用
两个模型都采用了 DeepSeekMoE 框架和 Multi-Token Prediction (MTP) 策略。MoE(混合专家)架构的核心思想是:不是让所有参数在每次前向传播中都参与计算,而是根据输入动态选择一部分"专家"网络来处理。这样做的好处是:
- 参数规模可以做得很大:总参数量达到万亿级别
- 推理成本可控:每次只激活少量参数(Pro激活49B,Flash激活13B)
- 专业化分工:不同专家可以专注于不同的知识领域或任务类型
这也意味着超长序列处理能力的突破——打开测试时扩展的新空间,也为在线学习等方向铺了路。
从预训练到后训练
先在巨量数据上预训练出基座模型,再通过后训练精细化成不同领域的专家,最后蒸馏成一个统一模型——V4 的训练大致就是这么个流程。
预训练阶段
Flash 在 32T token 上训练,Pro 多吃 1T,达到 33T。这里的"T"代表trillion(万亿)。为了让你有个直观的概念,如果一个人每秒读一个词,读完这些数据需要超过100万年!
后训练精细化
后训练分为两个关键步骤:
独立培育领域专家
-
监督微调(SFT):基座模型首先在高质量、领域特定的数据上进行微调,建立基础能力。
-
强化学习(RL):使用 Group Relative Policy Optimization (GRPO) 算法进行优化。GRPO是一种高效的强化学习方法,通过比较同一提示下多个输出的相对质量来更新模型,避免了传统RLHF中需要训练奖励模型的复杂性。
统一模型整合
通过 on-policy distillation(在线策略蒸馏)将所有独立培育的专家整合成一个统一的模型。这个过程确保了不同专家之间的知识能够有效融合,避免"各自为战"的问题。
让注意力处理百万 token
处理百万级别的上下文长度,传统的注意力机制会面临巨大的计算和内存挑战。V4 设计了两种创新的注意力架构:Compressed Sparse Attention (CSA) 和 Heavily Compressed Attention (HCA),并采用它们的交错混合配置。核心思路就是把 KV 缓存大幅压缩,再配合稀疏选择,让注意力计算的复杂度从 O(n²) 降到接近 O(n)。
CSA:压缩稀疏注意力
CSA结合了压缩和稀疏注意力两种策略:
- KV缓存压缩:每 m 个token的Key-Value (KV) 缓存被压缩成一个条目
- 稀疏注意力:每个查询token只关注 k 个压缩后的KV条目
这种设计大幅减少了注意力计算的复杂度,从传统的 O(n²) 降低到接近 O(n)。
HCA:重度压缩注意力
HCA在CSA的基础上更进一步,让更多的tokens被压缩成一个条目。CSA和HCA混合使用,在压缩率和精度之间取得了平衡。
让注意力不爆炸的三个小设计
RMSNorm归一化
对于CSA和HCA,在每个query的head和压缩KV条目的唯一head上,在核心注意力操作之前执行额外的RMSNorm操作。这个归一化避免了注意力logits爆炸,提高了训练稳定性。
Partial RoPE位置编码
在V4的架构中,位置编码对于模型理解序列中Token的先后顺序至关重要。RoPE(旋转位置编码)是目前大模型中最主流的位置编码方式,而 Partial RoPE 则是V4针对其特殊的注意力机制(特别是MLA多头潜在注意力)所做的一种优化设计。
关键创新点:
- 混合精度存储:对旋转位置编码(RoPE)维度使用BF16精度,对其余维度使用FP8精度
- 滑动窗口机制:对于每个query token,额外生成 n_win 个未压缩的KV条目,对应最近的 n_win 个tokens。在CSA和HCA的核心注意力中,这些滑动窗口中的KV条目会与压缩的KV条目一起使用
让注意力学会"忽略"
这是一个非常巧妙的设计!
传统痛点:如果当前Query与上下文中的所有Key都不相关(比如在处理无关噪声或极长距离的无效信息时),标准Softmax依然会强行把100%的权重分配给某些Key,导致模型"被迫关注"不重要的内容,产生干扰。
V4的解法:通过增大可学习参数 z'h,让 exp(z'h) 变大,分母变大,所有的 s{h,i,j} 都会变小。总注意力权重可以趋近于0。
直观理解:模型现在可以说:"这一行我看完了,但我觉得这里面没什么值得关注的",于是它把大部分注意力"漏"掉了,而不是强行分配给某个词。
适配CSA/HCA的压缩机制:在CSA和HCA中,Token被压缩成块(Blocks)。如果一个块内的信息很稀疏或无关,模型可以通过调整 z'h 来降低对该块的整体关注度。这种机制让模型在处理超长上下文时更加鲁棒,能够自动过滤掉那些"虽然存在但毫无意义"的压缩块,避免噪声累积。
FP4精度加速
在lightning indexer内的注意力计算使用FP4精度执行,这在极长上下文下加速了注意力操作。FP4是4位浮点数,相比传统的FP16或BF16,内存占用减少了4倍,计算速度大幅提升。
残差连接的进化
深层网络最怕什么?梯度消失和爆炸。残差连接缓解了这个问题,但到了万亿参数、几十上百层的规模,传统残差连接已经不够用了。V4 引入了 Manifold-Constrained Hyper-Connections (mHC),给残差连接加了"数学枷锁",让信号在深层网络中像水流一样平稳流动。
从残差连接到超连接
让我们对比一下几种连接方式:
| 特性 | 标准残差连接 | 标准超连接(HC) | mHC (DeepSeek-V4) |
|---|---|---|---|
| 残差变换 Bₗ | 普通线性矩阵,无约束 | 普通线性矩阵 | 双随机矩阵 (通过Sinkhorn算法约束) |
| 输入/输出映射 | - | 普通线性矩阵 | 非负有界 (通过Sigmoid约束) |
| 数值稳定性 | 深层网络易不稳定 | 一般 | 极高,适合超深网络 |
| 计算开销 | 极低 | 低 | 略高 (需运行Sinkhorn迭代),但可接受 |
| 核心目的 | 增加残差宽度 | 增加残差宽度 | 在增加宽度的同时保证训练稳定 |
mHC的核心思想
mHC就是给标准超连接加上了"数学枷锁",让残差信号在深层网络中像水流一样平稳流动,既不会泛滥(爆炸)也不会干涸(消失),从而让V4这种超大模型能够训得稳、效果好。
双随机矩阵的每一行和每一列的和都等于1,保证了信息在传递过程中不会无限放大或缩小。Sinkhorn 算法可以把任意正矩阵转换为双随机矩阵,虽然增加了计算开销,但对于万亿参数模型的稳定性来说,这个代价完全值得。
用 Muon 推动万亿参数
训练万亿参数模型就像推一辆超级重的车——普通优化器推不动或者推得慢,Muon 相当于给车装了个更高效的变速箱,用更少的力气跑更远。V4 引入了 Muon 优化器,带来了更快的收敛速度和更好的训练稳定性。但 Muon 和 ZeRO 分布式训练策略碰在一起,就需要一些巧妙的适配。
Muon的挑战
Muon优化器需要完整的梯度矩阵来计算参数更新,这与 Zero Redundancy Optimizer (ZeRO) 结合时面临挑战。ZeRO是一种分布式训练优化技术,通过将优化器状态、梯度和参数分散到多个GPU上来减少内存冗余。
混合ZeRO Bucket分配策略
为了解决这个问题,DeepSeek团队设计了一套混合的ZeRO Bucket分配策略:
稠密参数(Dense Parameters)
-
限制并行度 + 背包算法:限制ZeRO并行的最大规模,使用背包算法将参数矩阵分配给各个Rank(显卡/进程),确保每个Rank的负载大致平衡。
-
Padding对齐:为了高效执行reduce-scatter通信操作,每个Rank上的Bucket会进行填充(Padding),使其大小与所有Rank中最大的Bucket一致。
- 开销:在这种设置下(每个Rank管理不超过5个参数矩阵),内存开销通常小于10%。
-
超大规模数据并行处理:当数据并行(DP)的规模超过ZeRO的限制时,多余的DP组会冗余计算Muon更新。这是一种"用计算换内存"的策略,以减少总的Bucket内存占用。
MoE参数(Mixture of Experts)
-
独立优化专家:对每个Expert进行独立优化。
-
扁平化与重组:
- 将所有层、所有Expert的SwiGLU中的down projection矩阵扁平化并拼接
- 接着是up projection矩阵
- 最后是gate矩阵
-
整体Padding:将拼接后的长向量进行填充,确保它能均匀分布到所有Rank上,且不拆分任何逻辑上独立的矩阵。
-
无并行度限制:由于Expert数量众多,对MoE参数不限制ZeRO并行度,且Padding带来的开销微乎其微。
其他优化技巧
- 批量执行Newton-Schulz迭代:在同一Rank上,形状相同的连续参数会自动合并,从而可以批量执行Newton-Schulz迭代,提高硬件利用率。
- BF16稳定性:即使使用BF16(Bfloat16)精度进行矩阵乘法,Muon中的Newton-Schulz迭代依然保持稳定,这进一步提升了计算效率。
基础设施的极限压榨
训练和推理万亿参数模型,光有好的算法不够,还得把硬件压榨到极致。V4 在通信-计算重叠、Kernel DSL 和确定性计算上都做了深度优化。
通信和计算同时干
在专家并行(Expert Parallelism)中,V4 实现了一个细粒度的 EP 方案,将通信和计算融合到一个流水线化的内核中,实现通信-计算重叠。
核心思想:将专家分成多个"波"(waves),每个波包含一小部分专家。一旦某个波内的所有专家完成通信,计算就可以立即开始,无需等待其他专家。
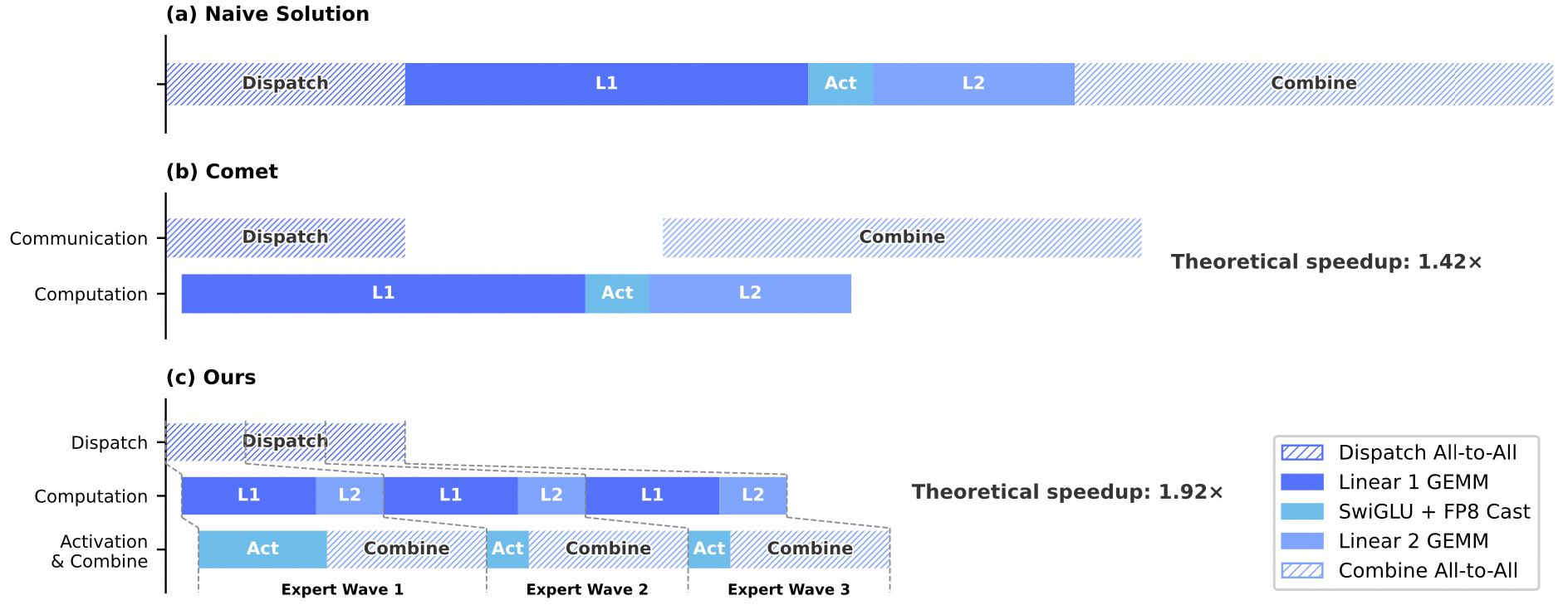
关键洞察:
- 完全的通信-计算重叠取决于计算-通信比率,而不仅仅是带宽
- 每GBps的互连带宽足以隐藏6.1 TFLOP/s计算的通信开销
- 这直接减少了后GEMM处理的开销,防止GEMM管道被激活函数计算阻塞,从而提高了整体计算吞吐量和资源利用率
TileLang:让 Kernel 写起来像高级语言
写 GPU Kernel 通常要在性能和开发效率之间二选一——要么手写 CUDA 追求极致性能但开发慢,要么用高级框架开发快但运行时开销大。TileLang 试图两者兼得:用领域特定语言描述计算逻辑,同时通过 Host Codegen 把运行时开销压到几乎为零。
TileLang 在 IR 层同时生成设备端 Kernel 和主机端 Launcher,后者经 TVM-FFI 降为原生 C++ 代码,再通过零拷贝张量交互和紧凑调用约定在运行时直接执行验证与 marshaling——完全绕过 Python 解释器,把 CPU 端调度开销压到微秒级以下。传统上主机端逻辑通常用 Python 写以获得灵活性,因此会产生固定的每次调用成本,Host Codegen 彻底解决了这个问题。
批量不变且确定性的核函数库
V4 提供了高效的批量不变且确定性的核函数库,确保训练和推理之间的逐位可重现性。
批量不变性确保任何给定token的输出保持逐位相同,无论其在批次中的位置如何。训练中的非确定性通常源于非确定性的累加顺序(比如原子加法指令),这个问题主要发生在反向传播期间。V4 通过精心设计的核函数消除了这个问题。
百万 token 怎么切分到多张卡
处理百万级别的上下文,单卡显存根本放不下。V4 设计了上下文并行(Contextual Parallelism, CP)策略,把超长序列切分到多张卡上并行处理,同时保证压缩后的 KV Cache 在分布式环境下对齐一致。
两阶段通信策略
边界数据交换与局部压缩
为解决压缩窗口可能横跨两个 Rank 的问题:
- 每个Rank i将其末尾的m个未压缩KV条目发送给下一个Rank i+1
- Rank i+1将这些接收到的边界数据与本地数据合并,执行压缩操作,生成长度固定(含少量Padding)的压缩KV块
此举确保了每个压缩组内的Token完整性,避免了因切分导致的特征失真。
全局收集与统一重组
- 所有CP Rank通过All-Gather操作交换本地压缩后的KV块
- 利用融合的Select-and-Pad算子将分散的块重组为全局连续的压缩KV序列,总长度为 cp_size · m · s
- 将所有Padding统一移至序列尾部
索引可见性处理
- 对于HCA和CSA索引器,各Query可见的压缩KV范围可通过规则预计算
- 对于CSA稀疏注意力,Top-k选择器直接指定可见的压缩KV索引
这套方案既保证了压缩的数学正确性——窗口不会跨边界被截断,又让分布式的 KV Cache 能高效对齐,长上下文训练的并行效率也就上来了。
把显存抠到每一个张量
训练大模型时,激活值占的显存非常可观。传统做法是按模块粒度做检查点(checkpoint),但这样粒度太粗,要么省不了多少显存,要么重计算开销太大。V4 的方案是精确到张量级别,你想重算哪个就标注哪个,框架自动帮你搞定。
传统方法的局限
传统的激活检查点机制在模块级粒度上权衡次优,而手动实现细粒度控制时开发复杂度极高。
V4 的创新方案
V4 提出了一种基于 TorchFX 的张量级自动激活检查点机制。开发者只需要在前向传播中标注哪些张量需要重计算,框架自动追踪计算图、反向遍历找到最小重计算子图、动态插入到反向传播中——全程不用手写一行反向传播逻辑。
性能优化
另外还有两个实用优化:零拷贝显存管理直接释放标注张量的 GPU 显存并复用重计算后的存储指针;自动去重则通过图追踪实时监控底层存储指针,自动识别并去重共享存储空间的张量(比如 Reshape 的输入与输出)。
说白了,你照常写 PyTorch 代码就行,框架在背后自动帮你把显存抠到最细,不用多写一行反向传播逻辑,也不会拖慢训练速度。
V4 带来了什么
V4 最核心的突破是三件事:第一,用 CSA/HCA 混合注意力把百万 token 上下文从理论可能变成了工程现实,而且推理成本可控;第二,mHC 超连接和 Muon 优化器的组合让万亿参数模型不仅能训得起来,还能训得稳、训得快;第三,从上下文并行到张量级检查点,一整套工程优化把硬件压榨到了极致。
对行业来说,V4 的经验很明确:单纯堆参数已经遇到瓶颈,架构创新和工程优化才是继续前进的关键。在保持高性能的同时降低推理成本,才能让大模型真正落地。DeepSeek 一直秉持开源理念,推动整个行业共同进步,这一点也值得肯定。
这也意味着超长序列处理能力的突破,打开了测试时扩展的新空间,也为在线学习和持续学习铺了路。我们可以期待上下文窗口继续拓展到千万甚至亿级 token,推理算法会越来越高效,专业领域能力也会持续增强。更让人兴奋的是在线学习和持续学习的突破——模型不再只在训练时学习,而是能在使用中不断进化。
参考资料
- DeepSeek-V4 Technical Report
- DeepSeekMoE Framework (Dai et al., 2024)
- Multi-Token Prediction Strategy
- Compressed Sparse Attention (DeepSeek-AI, 2025)
- Manifold-Constrained Hyper-Connections (Xie et al., 2026)
- Muon Optimizer (Jordan et al., 2024; Liu et al., 2025)
- Zero Redundancy Optimizer (Rajbhandari et al., 2020)
- TileLang (Wang et al., 2026)
如果这篇文章对你有帮助,欢迎点赞收藏,有问题也欢迎评论区聊。