论文:Greyhound: Hunting Fail-Slows in Hybrid-Parallel Training at Scale 作者:Tianyuan Wu, Wei Wang (HKUST); Yinghao Yu, Siran Yang, Wenchao Wu, Guodong Yang, Jiamang Wang, Lin Qu, Liping Zhang (Alibaba Group); Qinkai Duan (HKUST) 发表:USENIX ATC 2025
TL;DR
大规模混合并行训练中,GPU 和网络链路有时不会直接挂掉,而是"变慢"——这就是 fail-slow。GREYHOUND 通过 hook NCCL 调用做非侵入式迭代时间追踪,用 BOCD 算法在线检测异常变点,再用轻量 profiling + 微基准测试精确定位慢组件;缓解方面,借鉴滑雪租赁问题设计了从"什么都不做"到"检查点重启"的四级渐进策略。在万卡生产集群上检测准确率 >99%,256 H800 实验端到端吞吐提升 1.58 倍。
核心洞察
-
Fail-slow 不是小概率异常,而是大规模训练的常态。在万卡集群中,27 个大规模训练任务有 16 个遭遇 fail-slow,平均延迟完成时间 34.59%——测的是 JCT(Job Completion Time),跟无 fail-slow 的理想情况对比,说明在万卡规模下"坏得不彻底"的组件比"彻底坏了"更常见也更棘手。有数据支撑。
-
通信 fail-slow 比计算 fail-slow 更凶猛。计算 fail-slow(CPU 争抢、GPU 降频)频率低(<2%)、持续时间短(均值 10 分钟);通信 fail-slow(网络拥塞)频率高(40%)、持续时间长(均值 24 分钟),在大规模训练中更是频繁叠加,造成的减速远超计算问题。有数据支撑。
-
检测 fail-slow 的核心矛盾:所有 GPU 同时变慢,但只有一个是真凶。同步训练的固有特性导致一个慢组件拖慢全局,监控指标(如 SM 利用率)在所有 GPU 上同时下降,传统的节点级遥测无法定位根源。GREYHOUND 的解法是利用混合并行中不同并行组的通信模式做"组间对照",把变慢的组从正常组中筛出来。无数据支撑(设计洞察)。
-
缓解 fail-slow 是一个在线决策问题,而非简单的"重启"。传统做法把 fail-slow 当 fail-stop 处理——检查点+重启,但 GPT2-100B 的检查点就要近 100 分钟,比大部分 fail-slow 持续时间还长。GREYHOUND 借鉴滑雪租赁问题,让系统从低开销策略逐步升级,直到累计减速损失超过了更高开销策略的代价,再切换。有数据支撑。
开放问题:GREYHOUND 目前的检测机制依赖 NCCL 的顶层接口 hook,如果训练框架使用了非标准通信库或自定义集合通信原语,hook 点如何适配?
背景与动机
混合并行训练:为什么要搞这么复杂
训练万亿参数模型需要数千卡协同,单一并行策略无法兼顾效率:
| 并行策略 | 原理 | 通信量 | 适用范围 |
|---|---|---|---|
| TP(张量并行) | 切分单个算子到多卡 | 大(每个算子都需同步) | 单节点内 |
| DP(数据并行) | 复制模型,分片数据 | 中(梯度同步) | 节点内/间 |
| PP(流水线并行) | 按层分阶段,微批次流水 | 小(仅传递激活值) | 跨节点 |
混合并行 = TP + DP + PP 组合,在最大化训练效率的同时,也让故障的传播路径变得极其复杂。
Fail-stop vs. Fail-slow
| 维度 | Fail-stop | Fail-slow |
|---|---|---|
| 表现 | 进程崩溃、GPU 挂死 | GPU/网络变慢但仍在运行 |
| 检测 | 容易(心跳丢失) | 困难(所有 GPU 同时变慢) |
| 现有方案 | 检查点+重启、弹性框架 | 缺乏系统化方案 |
| 根因 | 硬件故障、运行时错误 | CPU 争抢、热降频、网络拥塞 |
现有方案主要解决 fail-stop,对 fail-slow 只是"提到但没深入"。Llama 3 报告和 MegaScale 都简要提及了 fail-slow,但没有系统刻画和解决方案。
万卡集群的 fail-slow 现状
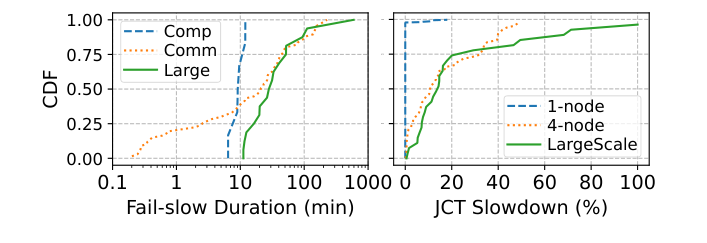
论文在阿里生产集群(4000+ 节点、10000+ GPU、RoCE 400Gbps)上做了系统刻画:
小规模探测(400 个单节点任务):
- 392 个成功完成的任务中,6 个遭遇计算 fail-slow(4 个 CPU 争抢,2 个 GPU 降频)
- 计算类平均持续 10 分钟,JCT 增加 11.79%
- 107 个 4 节点任务中,通信 fail-slow 发生率 40%,平均持续 24 分钟
大规模实际任务(27 个 ≥512 GPU 的训练任务):
- 16 个遭遇 fail-slow,平均 JCT 增加 34.59%
- 20% 的任务延迟超过 50%
- 平均 fail-slow 持续 72 分钟
- 根因:13 个纯网络拥塞,其余为网络+GPU 降频叠加
核心方法
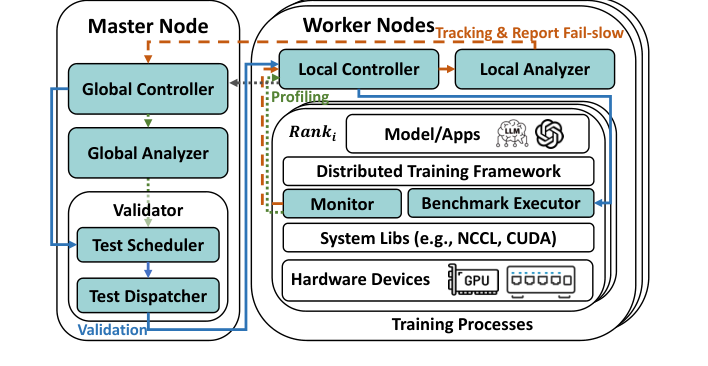
整体架构
GREYHOUND 采用 master-worker 架构,检测流程分三个阶段:追踪 → Profile → 验证。
阶段一:追踪(Tracking)
这是最关键也最巧妙的部分——不侵入训练框架,只 hook NCCL 调用。
迭代时间推断:训练循环中,集合通信操作(AllReduce、AllGather、ReduceScatter)呈现周期性模式。GREYHOUND 利用自相关函数(ACF)从通信调用序列中自动推断周期长度:
$$\text{ACF}(X)k = \frac{\text{Cov}(X_t, X{t+k})}{\text{Var}(X_t)} = \frac{\sum_{t=1}^{L-k}(X_t - \mu)(X_{t+k} - \mu)}{\sum_{t=1}^{L}(X_t - \mu)^2}$$
其中 $X$ 是通信调用时间戳序列,$k$ 是候选周期长度,$\mu$ 是序列均值。$\text{ACF}(X)_k$ 越大,$k$ 是真实周期的可能性越高。取首个超过阈值 $M=0.95$ 的 $k$:
$$\text{Period} = \arg\min_k (\text{ACF}(X)_k \geq M)$$
推断出周期后,迭代时间 = 相邻周期中同一通信操作的间隔。
异常检测——BOCD + 验证:拿到迭代时间序列后,用贝叶斯在线变点检测(BOCD)算法在线找变点。BOCD 为每个时间步 $t$ 维护一个 run-length $r_t$:如果不是变点则 $r_t = r_{t-1} + 1$,否则重置为 0。通过贝叶斯推断计算 $r_t = 0$ 的后验概率,超过阈值 0.9 则报告变点。
但 BOCD 会有误报(正常抖动被判为变点),所以加了验证:比较变点前后的平均迭代时间,差异 <10% 的视为正常抖动忽略。
阶段二:Profile
检测到慢迭代后,需要定位是哪个并行组出了问题。GREYHOUND 在每个 worker 上用 CUDA event 注入已 hook 的 NCCL 调用,测量每个通信组的执行时间。
核心思路是组间对照:在混合并行中,同一类型的通信组处理的数据量相同,执行时间理应一致。比如 4 个 DP 组的 AllReduce 通信量一样,如果一个组明显慢于其他组,那它里面就有 straggler。判断标准:执行时间超过组内中位数 10% 的组标记为可疑。
DP-0 AR0 ████████████ 1.2s
DP-1 AR1 ████████████ 1.1s
DP-2 AR2 ████████████ 1.1s
DP-3 AR3 ████████████████████ 1.8s ← 可疑!
阶段三:验证(Validation)
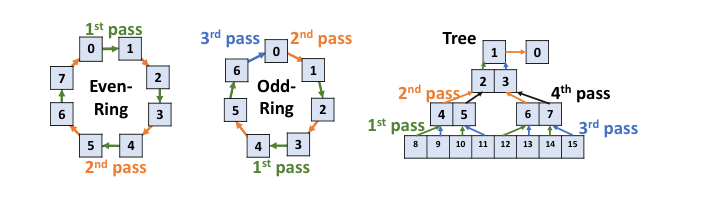
Profile 只能定位到可疑组,还需要在组内精确找出是哪个 GPU 或哪条链路慢。做法是短暂挂起训练(通过 trap NCCL 调用实现,无需重启),然后跑微基准测试:
计算验证:对组内所有 GPU 跑 GEMM 基准(FP8/FP16/FP32),独占所有 SM 核心测量真实性能。
通信验证:这是最巧妙的设计之一——不穷举所有 $O(N^2)$ 链路,而是利用集合通信的 Ring/Tree 拓扑结构,把集体通信拆成不重叠的 P2P 操作,$O(1)$ 轮即可覆盖所有链路:
- Ring 拓扑:偶数 rank 的 Ring 两轮覆盖(偶→奇,奇→偶),奇数 rank 加一轮
- Tree 拓扑:四轮覆盖(偶层左→父,偶层右→父,奇层左→父,奇层右→父)
每轮中同一方向的传输并行执行,因此耗时与组大小无关。
缓解机制:滑雪租赁启发的四级策略
检测到 fail-slow 之后怎么处理?GREYHOUND 设计了四级渐进式缓解:
| 策略 | 开销 | 对计算 fail-slow | 对通信 fail-slow |
|---|---|---|---|
| S1:忽略 | 无 | 无效 | 无效 |
| S2:调整微批次分布 | 低 | 有效 | 无效 |
| S3:调整并行拓扑 | 中 | 有效 | 有效 |
| S4:检查点+重启 | 高 | 根除 | 根除 |
为什么不能一上来就用 S4? 因为 GPT2-100B 检查点要近 100 分钟,而集群中 fail-slow 平均才 10-72 分钟——重启比等恢复还慢。
S2:调整微批次分布
数据并行把全局 batch 切成微批次均匀分配给各 DP 组。当某个组变慢时,减少它的微批次数、增加正常组的微批次数,让所有组的处理时间趋于一致:
$$\min_{m_1,\ldots,m_D} \max_{i=1,\ldots,D} m_i t_i \quad \text{s.t.} \quad m_i \in \mathbb{N}^+, \quad \sum_{i=1}^{D} m_i = M$$
其中 $D$ 是 DP 组数,$M$ 是总微批次数,$m_i$ 是分配给第 $i$ 个组的微批次数,$t_i$ 是该组处理一个微批次的耗时(由 profiling 获得)。本质上是最小化最慢组的时间,用 cvxpy 求解。
关键:微批次数变了,但全局 batch 大小和微批次大小都不变,梯度聚合时用加权平均保证训练正确性。
S3:调整并行拓扑
针对通信 fail-slow 的两个核心操作:
1. 把拥塞链路从重流量组换到轻流量组。DP 通信量远大于 PP 通信量(DP 每次同步数十 GB 梯度,PP 只传数十到数百 MB 激活值)。如果某条拥塞链路正被 DP 组使用,可以通过交换节点的 DP/PP 角色把这条链路"挪"给 PP 组,让轻流量走拥塞链路,重流量走健康链路。
Before: After:
DP ─── [congested] ─── PP ─── [congested] ───
PP ─── healthy ─── DP ─── healthy ───
2. 落后者合并(Straggler Consolidation)。多个落后者散布在不同 PP 阶段时,每个阶段都被拖慢。把所有落后者合并到最少数量的 PP 阶段中,因为同一阶段内取最慢的为准,多个落后者在一个阶段内不会叠加恶化。
拓扑调整的实现:暂停训练 → 将参数 dump 到内存 → P2P RDMA 交换参数 → 恢复训练。耗时约 1 分钟,与训练规模无关(每个 GPU 独立操作)。
滑雪租赁式决策
何时从 S1 升级到 S2、从 S2 到 S3?这个问题跟经典的滑雪租赁问题同构:
- "租滑雪板"= 继续忍受 fail-slow 带来的减速
- "买滑雪板"= 付出策略切换的开销一劳永逸
算法跟踪 fail-slow 已造成的累计减速(slow_iters × (t_slow - t_healthy)),当累计减速等于下一级策略的开销时,就切换——因为如果早知道会慢这么久,一开始就该用那级策略。
def mitigation_planner(event):
candidates = find_strategies(event.root_cause)
candidates.sort(key=lambda s: s.overhead)
id = 0 # 当前策略
while event.persist():
slow_iters = event.get_slow_iters()
slow_impact = slow_iters * (t_slow - t_healthy)
if slow_impact >= candidates[id].overhead:
candidates[id].apply()
id += 1
实验分析
检测准确率
| 算法 | 计算类准确率 | 计算类 FPR | 通信类准确率 | 通信类 FPR |
|---|---|---|---|---|
| 滑动窗口 | 99.5% | 0.0% | 93.5% | 1.5% |
| BOCD | 77.8% | 18.4% | 69.2% | 34.0% |
| BOCD+V | 100% | 0.0% | 99.1% | 0.0% |
BOCD+V(加验证)在计算类上达到完美准确率,通信类仅 2.3% FNR(来自连续 <10% 降速的罕见情况)。单独 BOCD 的 FPR 高达 18-34%,验证步骤把误报压到了零。
缓解效果
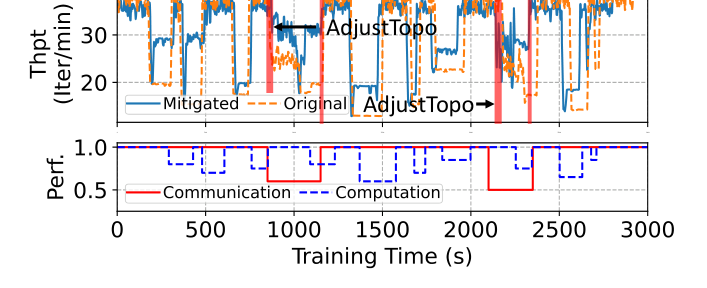
S2 微批次调整:单节点 8 GPU 实验中,注入弱/中/严重计算 fail-slow 后,迭代时间从 1.7 倍基线降至 1.1-1.3 倍,最高 1.59 倍优化。多个慢 DP 组时优化空间递减(所有组都慢就没法调整了)。
S3 拓扑调整:2 节点 16 GPU 实验中,PP=4 时严重拥塞降低迭代时间最高 1.23 倍,PP=8 时 1.14 倍。落后者合并:2 个散布在不同阶段的落后者导致 1.7 倍减速,合并到 1 个阶段后降至 1.3 倍。
端到端:256 H800 GPU(8TP, 16DP, 2PP)实验,注入 12 个 fail-slow 事件(2 通信 + 10 计算 + 复合场景):
- 无 GREYHOUND:吞吐 18.9 iter/min
- 有 GREYHOUND:吞吐 29.8 iter/min
- 提升 1.58 倍
开销
- 追踪阶段:平均开销 0.39%,最大 1.1%
- 验证阶段:H800 上计算基准 <1 秒,通信基准 <3 秒
- 微批次调整求解:512 DP 组时约 36 秒
- 拓扑调整:约 1 分钟(与规模无关)
- 对比 C/R:拓扑调整比磁盘检查点快 6.72 倍
深度理解问答
Q1:为什么 hook NCCL 调用而不是直接监控 GPU 指标?
直接监控 GPU SM 利用率、NVML 温度等指标看似更简单,但在同步训练中有一个致命问题:一个 GPU 变慢,所有 GPU 的 SM 利用率都会下降(因为同步屏障导致其他 GPU 在等待)。指标层面的"所有卡都慢"无法区分"谁是因谁是果"。hook NCCL 的好处是能精确测量每个通信组的耗时,通过组间对照找出真正的慢组。此外,NCCL 顶层接口在不同通信库(ACCL、MSCCL 等)间是统一的,保证框架无关性。
Q2:ACF 推断迭代周期的前提条件是什么?如果训练没有明显的周期性怎么办?
ACF 方法的前提是训练循环中通信操作呈现周期性模式——这在所有主流混合并行训练框架中都是成立的,因为每次迭代的通信模式高度重复。如果训练过程中动态改变并行策略(如弹性训练),周期模式会断裂,ACF 需要重新收敛。论文未讨论这种动态场景,推测在拓扑调整后 ACF 会自动重新检测新周期。
Q3:拓扑调整的"交换节点 DP/PP 角色"具体怎么实现?参数怎么搬家?
分四步:1) 暂停训练(trap NCCL 调用);2) 将 GPU 参数临时 dump 到主机内存;3) 通过 P2P RDMA 在节点间直接交换参数;4) 恢复训练。因为每张 GPU 独立操作,搬家时间与集群规模无关,只跟单卡参数量有关。H800 上 80GB 参数的搬家约 1 分钟。对比传统 C/R 需要写磁盘再读回来,内存直传+RDMA 绕过了 I/O 瓶颈,快了约 6.7 倍。
Q4:滑雪租赁模型在这里是不是一个过度的形式化?直接用固定阈值切换策略行不行?
固定阈值方案的问题在于:阈值设高了,短暂 fail-slow 会白等;设低了,持久 fail-slow 又切换太晚。滑雪租赁的核心洞察是"累计损失等于策略开销时切换"——这给出了一个无需先验知识的最优在线决策,竞争比为 2(最坏情况不超过最优策略的 2 倍)。这不是装饰性形式化,而是给了切换时机一个理论保证。实际中 S2 开销极低(秒级求解),S3 中等(约 1 分钟),S4 极高(数十到百分钟级),这种数量级差异让渐进式策略比固定阈值鲁棒得多。
Q5:GREYHOUND 在非 Megatron-LM 框架(如 DeepSpeed)上能用吗?
检测部分(GREYHOUND-DETECT)完全框架无关——它只 hook NCCL 顶层接口,不依赖训练框架内部逻辑,DeepSpeed、PyTorch FSDP 等都可以直接用。缓解部分(GREYHOUND-MITIGATE)需要框架层面的支持(修改微批次分配逻辑、支持运行时拓扑调整),目前以 Megatron-LM 插件形式实现,迁移到其他框架需要适配微批次调度和参数交换接口,工程量不算大但不是零成本。
总结
核心贡献
- 万卡集群 fail-slow 的首次系统刻画——量化了计算/通信 fail-slow 的频率、持续时间、影响程度,揭示了通信问题远比计算问题严重的现实,为后续研究提供了基准数据。
- 非侵入式、框架无关的检测——NCCL hook + ACF 迭代周期推断 + BOCD 在线变点检测 + 组间对照 profile + O(1) 链路验证,无需修改训练框架即可实现高精度检测,可直接部署到现有生产环境。
- 滑雪租赁启发的多级缓解机制——从"忽略"到"重启"四级渐进,累计减速超过策略开销时自动升级,理论竞争比为 2,首次为 fail-slow 缓解提供了有理论保证的在线决策框架。
局限性
- 无法检测计算-通信耦合型 fail-slow(极罕见但存在)
- 缓解机制依赖框架修改,非完全非侵入
- 连续小幅降速(<10%)可能被验证步骤漏报
适用场景
✅ 大规模混合并行训练(TP+DP+PP) ✅ 多租户共享集群(CPU 争抢、网络拥塞频发) ✅ 使用 NCCL 通信库的框架(Megatron-LM、DeepSpeed 等) ✅ 需要 7×24 无人值守运行的长时训练任务
❌ 不使用 NCCL 的训练框架(需适配 hook 点) ❌ 弹性训练场景(频繁改变并行度,ACF 周期推断需重新收敛) ❌ 对 <10% 的渐进式劣化敏感的场景
论文链接:USENIX ATC 2025