论文:Idleness is Relative: Exploiting Tool-Call Idle Windows for Offloading in Agentic Systems with MORI 作者:Tian Xia, Hanchen Li, Zhifei Li, Xiaokun Chen, Hao Kang, Yifan Qiao, Yi Xu, Ion Stoica(UC Berkeley 等) 发表:arXiv 2026
TL;DR
一句话:Agentic 工作负载(推理-工具调用-推理-工具调用的循环)下,KV Cache 放不下 GPU,但哪些该 offload 到 CPU?
之前的方法用"最近有没有访问过"或者"是不是在等工具调用"来做二元判断——要么在 GPU 要么在 CPU。问题是这些判断太粗糙了:一个程序可能"最近刚被访问过"但其实马上就要进入长达 30 秒的工具调用等待期,白白占着 GPU 显存。
MORI 的想法很简单:给每个程序算一个 0 到 1 之间的 idleness 分数(等工具调用的时间占总时间的比例),然后按分数排序。分数低的(忙的)留 GPU,分数高的(闲的)移 CPU。再配合一个动态调整 GPU/CPU 分区大小的机制,在 Claude Code 的真实编码代理任务上比最好的基线方法吞吐量提升 20%-71%,首个 token 延迟降低 18%-43%。
先讲清楚:问题到底是什么
要理解 MORI,得先把几个概念掰扯明白。
KV Cache 是干嘛的,为什么会不够
大模型推理时,每生成一个 token 都要参考前面所有 token 的 K 和 V 向量(KV Cache)。这些向量存在 GPU 的显存里(HBM)。一个 7B 模型处理一个 4K 上下文的对话,大约要占几百 MB 的 KV Cache。并发高的时候,比如 100 个对话同时跑,加起来就是几十 GB。
GPU HBM 很宝贵,通常一个 H200 只有 80GB。一个 Qwen-2.5 7B 模型自身就占 14GB 左右权重。剩下的 60GB 给 KV Cache 不够的时候,就得把某些对话的 KV Cache 搬到 CPU 内存甚至磁盘上——这就是 offloading。
Offloading 有代价,不能乱搬
把 KV Cache 从 GPU 搬到 CPU,再搬回来,都是要花时间的。把一个 500MB 的 KV Cache 从 HBM 拷贝到 DDR5 大概几毫秒,反过来也差不多。但如果一个程序 offload 到 CPU 后,马上又需要生成 token(工具调用立刻返回了结果),就得再搬回来——这一去一回的开销反而让延迟恶化。
所以 offloading 的核心是一个预测问题:这个程序接下来多久会需要 GPU? 如果它马上就要用,别挪;如果它很久都不用,挪走划算。
Agentic 负载让这个问题变难了
普通的 chat 对话是"用户发一句 → 模型回复一串 → 用户再发一句"。但 Agentic 程序是循环的:
- 模型生成推理 token(比如思考下一步调用什么工具)→ 占 GPU
- 生成 tool-call 指令 → 执行工具(文件读写、代码执行、API 调用等)→ 不占 GPU,等结果
- 工具结果返回,模型接着生成 → 又占 GPU
问题出在第 2 步的等待时间。它可以是:
- 几毫秒:一个本地数学计算工具瞬间返回
- 几百毫秒:一次数据库查询
- 几秒:一次网络 API 调用
- 几十秒甚至几分钟:等待用户确认、执行耗时脚本
时间跨度从 10⁻³ 秒到 10² 秒,差了 5 个数量级。
现有方法为什么不够
理解了问题之后,再看现有方法的局限就很清楚了。
方法一:LRU(最近最少使用)
LRU 说:"把最近最久没用的 KV Cache 挪走。"
但 LRU 只看"最后一次访问是什么时候",不看"这个程序接下来会怎么样"。在 agentic 场景下,一个程序可能刚刚生成完一个工具调用指令(所以它"最近被访问过"),但接下来要等 30 秒工具返回——LRU 会认为它很"热门",把它留在 GPU 上。但实际上它完全不需要 GPU。
更严重的是反向问题: 一个程序其实一直在忙碌生成 token(busy phase),但刚好轮到别的程序在 GPU 上跑,它的"最后访问时间"就变旧了。LRU 会把它 offload——但它其实非常活跃。
方法二:二元 busy/idle 标签
这是一个自然的改进:检测"这个程序是不是正在等工具调用返回"。如果在等,就标 idle,offload 到 CPU;否则标 busy,留 GPU。
但现实中,"等不等"不是一个二元问题。比如:
- 程序 A:正在生成推理 token,完全 busy(idleness ≈ 0)
- 程序 B:刚发了一个 HTTP 请求,通常 200ms 返回(idleness ≈ 0.3)
- 程序 C:正在等用户在网页上点按钮,可能几秒也可能几分钟(idleness ≈ 1.0)
如果 GPU 只能放下 2 个程序,二元标签会说:"A busy → 留 GPU,B idle → 挪 CPU,C idle → 挪 CPU"。但实际上 B 和 C 的"闲"程度差了一个数量级——B 可能马上就要回来,挪出去又搬回来反而亏。
二元标签的根本问题是:它扔掉了"闲到什么程度"这个信息。 所有 idle 程序被一视同仁,其中有些其实很"忙"。
方法三:固定 Timer
有人可能说,那就设个定时器呗——一个程序 500ms 内没动静就 offload。
但时间跨度从毫秒到分钟,设多少都不对:
- 设短了(如 100ms):很多等了 150ms 就回来的程序会被无谓 offload,来回搬的开销全浪费了
- 设长了(如 10s):那些等 30 秒的程序白白占着 GPU 显存 10 秒,资源没利用
- 固定值对不同任务、不同系统配置、不同并发度都不一样,根本调不出一个普适的数
MORI 的思路
MORI 做了三件事:
1. 用连续的 idleness 分数取代二元标签
对每个程序 p,idleness 定义为:
就是"等工具调用的时间"除以"总时间"。0 表示从不等待(纯推理),1 表示一直在等(纯工具调用)。
这个分数是连续且相对的——连续是说它捕捉了程度,相对是说它跟其他程序比才有意义。
2. 按 idleness 排序后分层
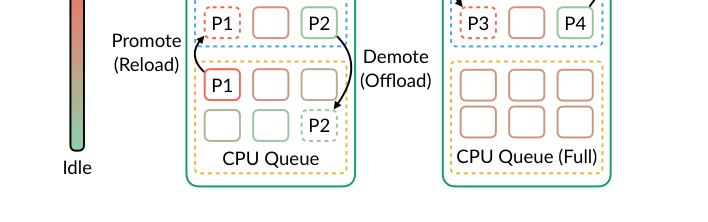
把所有程序按 idleness 分数从小到大排序,然后分三层:
- GPU Queue:idleness 最低的一批,存在 GPU HBM 上
- CPU Queue:idleness 中等的一批,存在 CPU DRAM 上
- Swap:idleness 很高的一批,存在磁盘/NVM 上
关键是这三层的边界不是固定的,会根据 GPU 和 CPU 上的压力动态调整。
3. 动态调整分区边界
系统实时看 GPU 压力和 CPU 压力。如果 GPU 显存很紧张(排队等待 GPU slot 的程序很多),就把 GPU 分区的边界往下挪——把 idleness 相对较高但当前还在 GPU 上的程序 demote 到 CPU。反之如果 CPU 内存紧张但 GPU 有空间,就 promote 回 GPU。
这个动态调整解决了"固定 timer 设多少都不对"的问题——不需要固定阈值,系统自己根据当前资源压力决定谁该挪。
实验结果
用 Claude Code 的真实编码代理工作负载测试,模型包括 Qwen-2.5 7B、Qwen-3 30B-A3B、Llama-3.1 70B。
基线方法 SMG 是当前 SOTA 的通用 offloading 方法,TA+O 是 Token Attention + Offloading 的方案。
| 配置 | 指标 | MORI vs SMG | MORI vs TA+O |
|---|---|---|---|
| H200 + Qwen-2.5 7B (DP=1) | Throughput | +71% | +20% |
| H200 + Qwen-2.5 7B (DP=1) | TTFT | -43% | -18% |
并发越高(如 80 用户),MORI 的优势越明显——因为并发越高,资源越紧张,"选谁 offload"的决策就越重要,选得好收益就越大。
值得记录的几点
- idleness 这个概念本身没什么数学上的高深之处——它就是一个时间占比。MORI 的贡献在于把它作为 offloading 的核心决策信号,并证明它在 agentic 场景下比 LRU 或二元标签好得多。
- 分层队列 + 动态边界是 MORI 的工程创新。连续分数解决了"程度"问题,动态边界解决了"固定阈值不对"的问题。
- 论文未量化调度开销是个遗憾。idleness 采样和排序、promote/demote 决策、数据迁移都有成本。论文说调度频率远低于 tool-call 频率,所以 amortized 开销可接受,但没有给出具体数字。
- 对非 agentic 负载,MORI 的 idleness 指标会退化为请求间隔——区分度不大。但分层架构本身仍然有效,只是 idleness 这个信号不那么有用了。
一句话总结:资源紧张时,不仅要问"最近谁用了",还要问"谁现在真的需要"——后者在 agentic 场景下是个更有区分度的信号。